

Введение. Журналы кликов в поисковой системе являются бесценным ресурсом, который может предоставить богатый источник данных о пользовательских предпочтениях в их результатах поиска. Анализ журналов переходов по ссылкам может использоваться во многих связанных с поиском приложениях, таких как ранжирование веб-поиска, прогнозирование популярности сайта или прогнозирование удовлетворенности пользователей. При анализе журналов кликов основной вопрос заключается в том, как построить модель кликов, чтобы вывести воспринимаемую пользователем релевантность для каждой пары запрос-документ на основе огромного количества данных поисковых кликов. Используя модель кликов, коммерческая поисковая система может лучше понять поведение пользователей при поиске и предоставить улучшенные пользовательские сервисы.
Модель CCM. В работе [1, 2] представлена модель click chain model (CCM), в переводе означает модель цепочки кликов. CCM основа на циклическом процессе взаимодействия пользователя с результатами поисковой системы.
При создании CCM авторы отталкивались от следующих предположений: пользователи являются однородными: их информационные потребности одинаковы при одинаковом запросе; вероятность клика определяется исключительно вероятностью просмотра и релевантностью документа в данной позиции; просмотр документов проводится в строго последовательном порядке без перерывов.
Модель в виде блок-схемы представлена на рисунке 1.
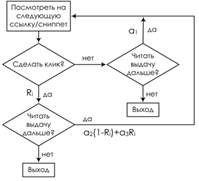
Рис. 1 Модель ССМ. Блок схема
Модель в виде байесовской сети представлена на рисунке 2.
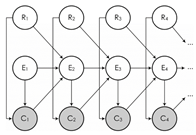
Рис. 2 Модель ССМ в виде байесовской сети
Пользователь начинает проверку результатов поиска из документа с самым высоким рейтингом [3]. В каждой позиции i пользователь может выбрать или пропустить документ di в соответствии с предполагаемой релевантностью. В обоих случаях, пользователь может продолжить изучение или отказаться от текущего запроса. Вероятность клика на текущий документ составляет Ri. Вероятность пропуска документа di составляет α1. Если же был сделан клик, то продолжение просмотра определяется релевантностью просмотренного документа и параметрами α2, α3.
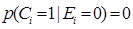 (1)
(1)
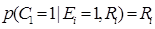 (2)
(2)
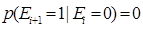 (3)
(3)
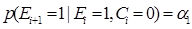 (4)
(4)
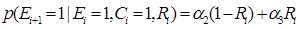 (5)
(5)
где Ci – клик на этой позиции
Ei – просмотр описания ссылки на документ, показанный на позиции i
Преимуществами данной системы является то, что она является масштабируемой и инкрементной, что идеально подходит для аналитических задач, которые используют журналы кликов, которые постоянно растут.
Модель DBN. Авторами работы [4] была предложена модель dynamic Bayesian network (DBN), которая переводится как динамическая байесовская сеть.
При создании CCM авторы основывались на гипотезах, предложенных ранее: клик происходит тогда и только тогда, когда пользователь изучил URL-адрес и посчитал его релевантным; пользователь делает линейный переход по результатам и решает, нажимать ли, основываясь на воспринимаемой релевантности документа; пользователь решает проверить следующий URL-адрес, если не удовлетворен выбранным URL-адресом (на основе фактической релевантности). Отличительной особенностью данной модели являются предположения: щелчок не обязательно означает, что пользователь удовлетворен выбранным документом (авторы пытаются различить воспринимаемую релевантность и фактическую релевантность); нет ограничений по количеству кликов, которые пользователь может сделать во время поиска. Ее модель в виде байесовской сети представлена на рисунке 3.
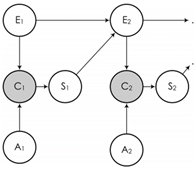
Рис. 3 Модель DBN. Байесовская сеть
Пользователь кликает на документ только в том случае, если пользователь посмотрел описание документа и был им привлечен. Вероятность того, что документ окажется привлекательным для пользователя составляет ai. После того, как пользователь щелкнет и посетит URL-адрес, существует определенная вероятность si того, что он будет удовлетворен этим URL-адресом. С другой стороны, если он не перейдет по ссылке, он не будет удовлетворен. Как только пользователь удовлетворен посещенным им URL-адресом, он прекращает поиск. Если пользователь не удовлетворен текущим результатом, существует вероятность γ, что пользователь просмотрит описание следующего документа. С другой стороны, существует вероятность 1 - γ, что пользователь откажется от своего поиска. Другими словами, γ измеряет настойчивость пользователя. Если пользователь не исследовал позицию i, он не будет проверять последующие позиции.
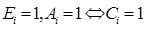 (6)
(6)
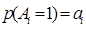 (7)
(7)
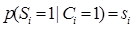 (8)
(8)
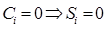 (9)
(9)
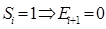 (10)
(10)
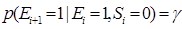 (11)
(11)
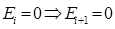 (12)
(12)
В отличие от других, DBN имеет две переменные ai и si, связанные с релевантностью документа. Первая измеряет вероятность клика на основе описания документа и связана с воспринимаемой релевантностью. Вторая - вероятность того, что пользователь удовлетворен, если он нажал на ссылку.
Таким образом преимуществом модели является разделение воспринимаемой и фактической релевантности документа. В некоторых случаях она различается, несмотря на существование сильной корреляции между ними.
Модель TCM. В работе [5] представлена модель task-centric click model (TCM), в переводе модель клика, ориентированного на задачу. Традиционно пользовательские сеансы получают из последовательной последовательности действий пользователя по поиску и просмотру в течение фиксированного интервала времени. Эти сеансы могут быть разделены на две категории: сеанс запроса (рисунок 4) и сеанс поиска (рисунок 5), где первый относится к действиям по просмотру информации в отдельном запросе, в то время как последний охватывает все запросы и просмотры, которые пользователь выполняет для удовлетворения своих информационных потребностей.
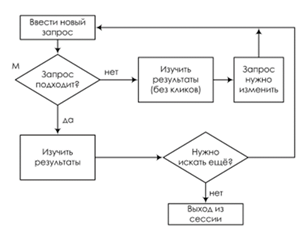
Рис. 4 Модель ТСМ Блок-схема сеанса запроса
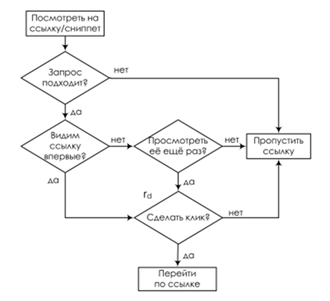
Рис. 5 Модель ТСМ. Блок-схема сеанса поиска
В начале было выдвинуто два предположения: если запрос не соответствует намерению пользователя, он не будет выполнять щелчки, а будет создавать новый запрос; когда документ был исследован ранее, вероятность того, что пользователь нажмет на него, будет ниже, если повторный запрос выдаст его.
TCM использует две двоичные случайные величины, M и N, для характеристики. M представляет, является ли запрос хорошим или, другими словами, соответствует ли он намерению пользователя, а N представляет, хочет ли пользователь продолжить свой поиск, если его предыдущий запрос является хорошим. Стоит отметить, что значение M будет влиять на то, как модель интерпретирует поведение пользователя для текущего запроса. Вероятность клика определяется релевантностью документа, обозначенной как r. С другой стороны, если документ был проверен ранее, пользователь решит, является ли документ все еще «свежим», который характеризуется как случайная переменная F. Для не свежего документа его поведение при щелчке больше не определяется исключительно его актуальностью, поэтому нужно охарактеризовать свежесть, чтобы интерпретировать поведение кликов пользователей. Другими словами, пользователь будет стремиться пропустить не свежий документ, так как он мог быть исследован ранее.
Задача содержит m запросов (сессий), причем каждый сеанс запросов содержит n упорядоченных документов. Коэффициент j-й обозначает позицию документа в i-й сессии запроса. α1 представляет вероятность Mi = 1, извлеченную из контекстной информации всей задачи. α2 и α3 являются параметрами, которые имеют аналогичные значения [6].
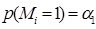 (13)
(13)
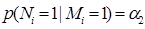 (14)
(14)
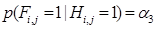 (15)
(15)
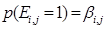 (16)
(16)
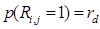 (17)
(17)
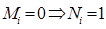 (18)
(18)
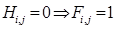 (19)
(19)
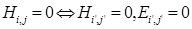 (20)
(20)
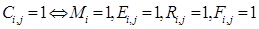 (21)
(21)
где β – обозначает вероятность того, что пользователь просмотрит описание.
Таким образом главным отличием и преимуществом данной модели является то, что модель рассматривает поведение пользователя на уровне сессии. Что в свою очередь ведет к повышению точности моделирования.
Модель SCM. Авторами работы [7] была предложена session click model (SCM), в переводе модель клика по сеансу. За основу была взята модель DBN.
Авторы работы основывались на следующих предположениях: пользователь может сформулировать свой запрос неточно и, при этом, удовлетвориться нерелевантным документом или проигнорировать релевантный; пользователь перед кликом на документ всегда просматривает описание ссылки; пользователь просматривает выдачу последовательно при этом может сделать один, несколько или не одного клика по документам и покидает сессию, как только находит интересующий его документ; вероятность того что пользователь будет кликать на ранее просмотренный документ меньше.
Используя вышеперечисленные предположения, авторы разработали модель структура графа, зависит только от количества запросов в сессии, а не от конкретной сессии. На рисунке 6 приведена предлагаемая модель клика.
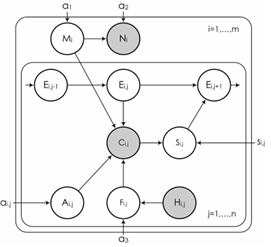
Рис. 6 Модель SCM. Байесовская сеть
Набор условных вероятностей, завершающий формальное определение модели.
Параметр ai,j определяет привлекательность документа, а точнее, соответствующего ему элемента на странице выдачи. Этот параметр влияет на вероятность клика. Параметр si,j можно интерпретировать как пертинетность документа: если запрос соответствовал потребностям пользователя, и пользователь закончил просмотр выдачи кликом по этому документу, значит, документ оказался ему полезным [8].
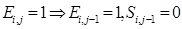 (22)
(22)
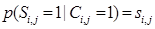 (23)
(23)
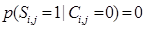 (24)
(24)
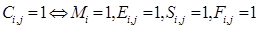 (25)
(25)
В качестве оценки релевантности документа, как и в DBN, используется:
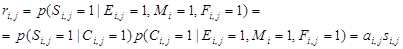 (26)
(26)
Заключение. Многообразие моделей поведения пользователя говорит о распространенности и важности данной проблемы. Используя данные математические модели для улучшения пользовательских сервисов и релевантности выводимой информации необходимо выбирать между высокой точностью модели и высокой производительность. Таким образом, извлечение релевантной информации из журналов пользователей является сложной, но ценной задачей для ранжирования в веб-поиске.
Библиографическая ссылка
Крюкова Я.Э., Гришунов С.С., Рыбкин С.В. ИССЛЕДОВАНИЕ СОВРЕМЕННЫХ МОДЕЛЕЙ ПОВЕДЕНИЯ ПОЛЬЗОВАТЕЛЕЙ В СЕТИ // Международный студенческий научный вестник. – 2019. – № 1. ;URL: https://eduherald.ru/ru/article/view?id=19538 (дата обращения: 19.04.2024).