

Введение. В настоящее время в задачах генерации фотореалистичных изображений при помощи компьютеров постепенно всё более значимое место занимают приложения с применением нейронных сетей. Особенно там, где стандартные алгоритмы приводят к относительно большой ошибке [1]. Однако далеко не последнюю роль в получении хороших результатов в генерации изображений при помощи нейросетей играет правильный подбор и обработка обучающих данных.
Качество обучения нейронной сети зависит не только от алгоритма обучения, но и от качества обучающей выборки [2] в частности и подготовки данных в целом [3]. В данной работе предлагается подход к обучающим данным, является развитием подходов, представленных в работах [4, 5].
Анализ подходов к предобработке данных для обучения. В работе [4] входные данные представляют собой последовательность сгенерированных при помощи трёхмерного редактора изображений голов людей, используемых для предиктивного обучения. На каждом последующем изображении голова повёрнута на 30 градусов относительно предыдущего (рис. 1). Данный подход позволил с успехом выполнить цель работы [4].

Рисунок 1 - Пример используемых в [4] изображений.
В работе [5] входные данные представляют собой набор из 809 поднаборов изображений различных стульев, каждый из которых содержит по 62 изображения объекта с разных сторон: 31 изображение по кругу с возвышением в 20 и 30 градусов. Изображения имеют разрешение 128 на 128 пикселей. Изображение стула расположено на белом фоне (рис. 2).

Рисунок 2 – Пример используемых в [5] изображений.
В данной работе предложен комбинированный подход к компоновке и обработке входных данных для задач генерации фотореалистичных изображений. Архитектурное решение нейронной сети, для которого предложен данный подход, изложен в [6]. В [6] предлагается создать генеративную сеть из трёх свёрточных подсетей для каждого канала изображения – красного, синего и зелёного, в центральной части расположить долговременно-кратковременную память, а непосредственно для генерации изображения на выходе расположить четыре развёрточные нейронные сети, три для стандартных канала изображения и четвёртый для маски объекта на изображении. Так же для улучшенного механизма обучения в [6] предложено помимо генеративной сети создать дискриминирующую сеть, устанавливающую степень правдоподобности сгенерированного изображения и изменяющую тем самым переменные уравнений обучения генеративной сети.
Стандартное изображение входного множества имеет размерность 128 на 128 пикселей. На белом фоне в изображении расположен какой-либо объект, имеющий конечный объём. Изображения сгруппированы по классам, например, «стул», «стол», «кровать». Каждый класс делится на несколько типов, характеризуемых своими качественными характеристиками: текстурой, цветом, аспектами форм. Например, класс «стол» делится на типы «журнальный столик из красного дерева» и «светлый компьютерный стол». Каждому типу соответствует набор изображений с одним и тем же объектом, изображённым с разных углов зрения и при разном освещении (рис. 3).






Рисунок 3 – Пример изображений.
Изображения являются сгенерированными при помощи компьютерной трёхмерной графики. Шаг вращения объекта по горизонтали составляет 20 градусов, что даёт по 18 изображений объекта на одно значение широты. Угол возвышения камеры варьируется от -80 до 80 градусов с тем же шагом 20 градусов. Итого на одну освещённость на один тип приходится по 162 изображения одного объекта.
Общее количество классов и типов, а так же наборов свойств, применяемых для обучения, может меняться в зависимости от реакции сети на обучение. В среднем для обучения сети желательно использовать порядка 100 классов, каждый по десять типов. Итого 162 000 изображений.
При помощи таких данных можно сгенерировать изображение разными способами. В работах [4, 5] представлены сходные подходы, в которых генерация изображений достигается благодаря глубоким развёрточным нейросетям. Эти работы различаются методами обучения и возможностями генерации. В данной работе будет рассмотрено преобразование данных для архитектуры, представленной в работе [6].
Математическая модель преобразования данных. Данные преобразуются следующим образом. Изначально белый фон перед подачей в сеть заменяется чёрным для того, чтобы избежать излишних значений возбуждений нейронов в сети. Затем изображение разбивается на три потока, т. е. по факту его можно представить как трёхмерную матрицу размерностью 128х128х3, где каждая ячейка содержит значение от 0 до 1, при чём 0 означает отсутствие компонента, а 1 – максимальное его присутствие в соответствующем пикселе.
Далее эта трёхмерная матрица проходит преобразование с использованием свёрток. Пусть входное изображение является
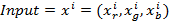 (1)
(1)
где 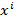 - изображение в каналах RGB,
- изображение в каналах RGB, 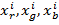 - изображения, состоящие исключительно из каналов R, G, B соответственно, i – номер изображения в выборке. Тогда карта свойств, полученная после прохождения двумерной матрицы через операцию свёртки, будет
- изображения, состоящие исключительно из каналов R, G, B соответственно, i – номер изображения в выборке. Тогда карта свойств, полученная после прохождения двумерной матрицы через операцию свёртки, будет
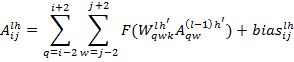 (2)
(2)
где i, j, q, w – положение нейрона в карте свойств по вертикали и горизонтали, l – номер слоя, h – номер карты свойств, A – активация соответствующего нейрона, W – весовой коэффициент в ядре свёртки, bias – смещение соответствующего нейрона, F – функция активации нейрона. В итоге после прохождения всех операций свёртки и макс-пулинга, на выходе многослойного персептрона образуется многокомпонентный вектор, состоящий из 1162 компонент. Сюда входит 1000-элементный вектор классификации и 162-х элементный вектор угла зрения.
Следующий этап не является преобразованием данных как таковым. Это этап обучения свёрточной подсети по классическому алгоритму обратного распространения ошибки. Модификация весовых коэффициентов и ядер происходит по формулам:
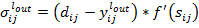 (3)
(3)
ошибка выхода нейрона последнего слоя MLP свёрточной сети, где 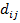 - целевое значение выхода нейрона,
- целевое значение выхода нейрона, 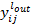 – действительное значение выхода нейрона,
– действительное значение выхода нейрона, 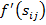 - производная активационной функции нейрона,
- производная активационной функции нейрона, 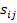 - взвешенный вход нейрона.
- взвешенный вход нейрона.
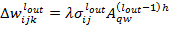
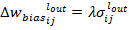 (4)
(4)
где 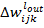 - изменение веса k дендрита, связывающего текущий выходной нейрон и нейрон
- изменение веса k дендрита, связывающего текущий выходной нейрон и нейрон 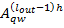 ,
, 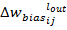 - изменение смещения текущего выходного нейрона,
- изменение смещения текущего выходного нейрона, 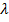 – скорость обучения. Ошибка
– скорость обучения. Ошибка 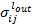 передаётся на связанные с текущим нейроны предыдущего слоя. Далее каждый нейрон скрытых слоёв высчитывает свою ошибку как:
передаётся на связанные с текущим нейроны предыдущего слоя. Далее каждый нейрон скрытых слоёв высчитывает свою ошибку как:
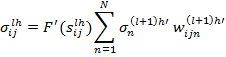 (5)
(5)
где N – количество связанных с данным нейроном синапсов. Ошибка 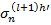 соответствует нейрону, с которым связан текущий нейрон синапсом n, который имеет вес
соответствует нейрону, с которым связан текущий нейрон синапсом n, который имеет вес 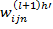 . Величины изменений весов связи и корректировки смещения высчитывается, соответственно :
. Величины изменений весов связи и корректировки смещения высчитывается, соответственно :
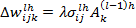
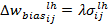 (6)
(6)
Результирующий вектор подаётся на вход долговременной-кратковременной памяти для накопления знаний – long short term memory - LSTM. По примеру работа [4, 6], LSTM служит для предиктивного обучения на основе пяти последовательных кадров. На вход LSTM подаётся пять полученных векторов, и данная подсеть экстраполирует эти вектора в шестой, который при развёртке преобразуется в выходное изображение.Для проведения такого обучения в работе [4] используется метод градиентного спуска, и в качестве функции потери используется сумма среднеквадратичной ошибки и соревновательной ошибки:
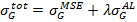 (7)
(7)
При чём соревновательная ошибка рассчитывается исходя из выхода сети-дискриминатора из работ [4, 6] по следующим формулам:
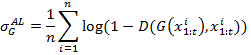 (8)
(8)
где 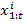 - обучающая последовательность кадров,
- обучающая последовательность кадров, 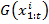 - предсказанное генеративной сетью изображение на основе обучающей последовательности,
- предсказанное генеративной сетью изображение на основе обучающей последовательности, 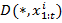 – выход дискриминатора, n – количество кадров в обучающей последовательности. Для обучения дискриминатора используется функция ошибки:
– выход дискриминатора, n – количество кадров в обучающей последовательности. Для обучения дискриминатора используется функция ошибки:
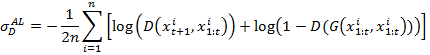 (9)
(9)
Для обычной генерации изображения после обучения непосредственно на вход генеративной части следует подать вектора класса, вида и транформации, которые описаны в [6]. Над вектором проводятся операции развёртки для всех каналов таким образом, что значение выхода нейрона (I, j) слоя l карты свойств h представляет собой
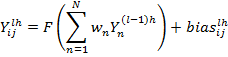 (10)
(10)
Или же, если выделить матрицу фильтра, то:
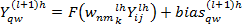 (11)
(11)
где 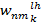 - элемент (n,m) транспонированной матрицы ядра фильтра k.Анпулинг происходит по формуле
- элемент (n,m) транспонированной матрицы ядра фильтра k.Анпулинг происходит по формуле
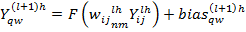 (12)
(12)
где 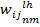 - весовой коэффициент в карте пулинга для соответствующего нейрона из свёрточной сети. В обычном случае карта анпулинга представляет собой матрицу 2 на 2 с одним элементом, отличным от нуля. Этот элемент проставляется в момент пулинга и указывает на местоположение максимального элемента в пулинге и, соответственно, на местоположение максимального элемента при анпулинге.На выходе всех четырёх потоков, описанных в [6], получаются матрицы 128 на 128 элементов, которые следует сложить для получения финального изображения. Для получения более понятной картинки в качестве постобработки изображения можно заменить чёрный фон на белый.
- весовой коэффициент в карте пулинга для соответствующего нейрона из свёрточной сети. В обычном случае карта анпулинга представляет собой матрицу 2 на 2 с одним элементом, отличным от нуля. Этот элемент проставляется в момент пулинга и указывает на местоположение максимального элемента в пулинге и, соответственно, на местоположение максимального элемента при анпулинге.На выходе всех четырёх потоков, описанных в [6], получаются матрицы 128 на 128 элементов, которые следует сложить для получения финального изображения. Для получения более понятной картинки в качестве постобработки изображения можно заменить чёрный фон на белый.
Вывод. Таким образом предложенный в данной статье подходя является развитием и в некотором роде совокупностью подходов, предложенных в [4] и [5]. Увеличение количества изображений с разных углов увеличивает возможности к генерации изображений, а применение комбинированного подхода к обучению позволяет добиться более качественного обучения.